New Pwn
年初随便写的+搬的一点东西,贴在这里。图片来自星盟安全团队的pwn教程。
binary
Linux用文件头识别文件而非后缀名。
文件存在磁盘中,运行时载入内存。
解释型语言不需要编译出可执行文件,用解释器解释后交给CPU执行。
printf(“%p”,xxx)打印地址。
c compile简要过程
graph LR
A["test.c(src)"]
B["test.s(asm)"]
C["test.o(obj)"]
D["a.out"]
A--编译-->B--汇编-->C--链接-->D
可执行文件
linux使用ll查看权限:-rwx
chmod提权
Windows : PE:
- 可执行程序.exe
- 动态链接库.dll
- 静态链接库.lib
Linux: ==ELF==:
- 可执行程序.out
- 动态链接库.so
- 静态链接库.a
ELF结构
graph LR
A["test.elf"]
B["header(1/2)"]
C["sections"]
D["header(2/2)"]
E["ELF header(ELF文件头总结构)"]
F["Program Header table(程序头表/段表)"]
G["Code"]
H["Data"]
I["Section's names"]
J["Section Header Table(节头表)"]
A-->B & C & D
B-->E & F
C-->G & H & I
D-->J
磁盘中的ELF和内存中的ELF(进程内存映像)
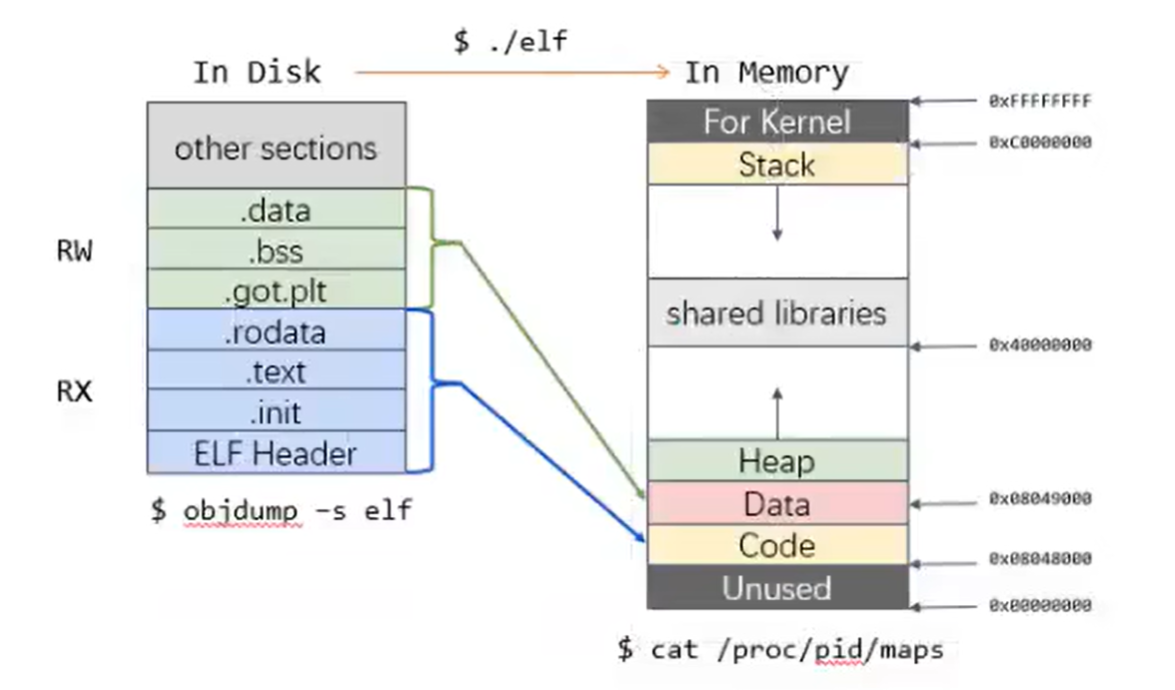
写入数据总是从低地址向高地址写。
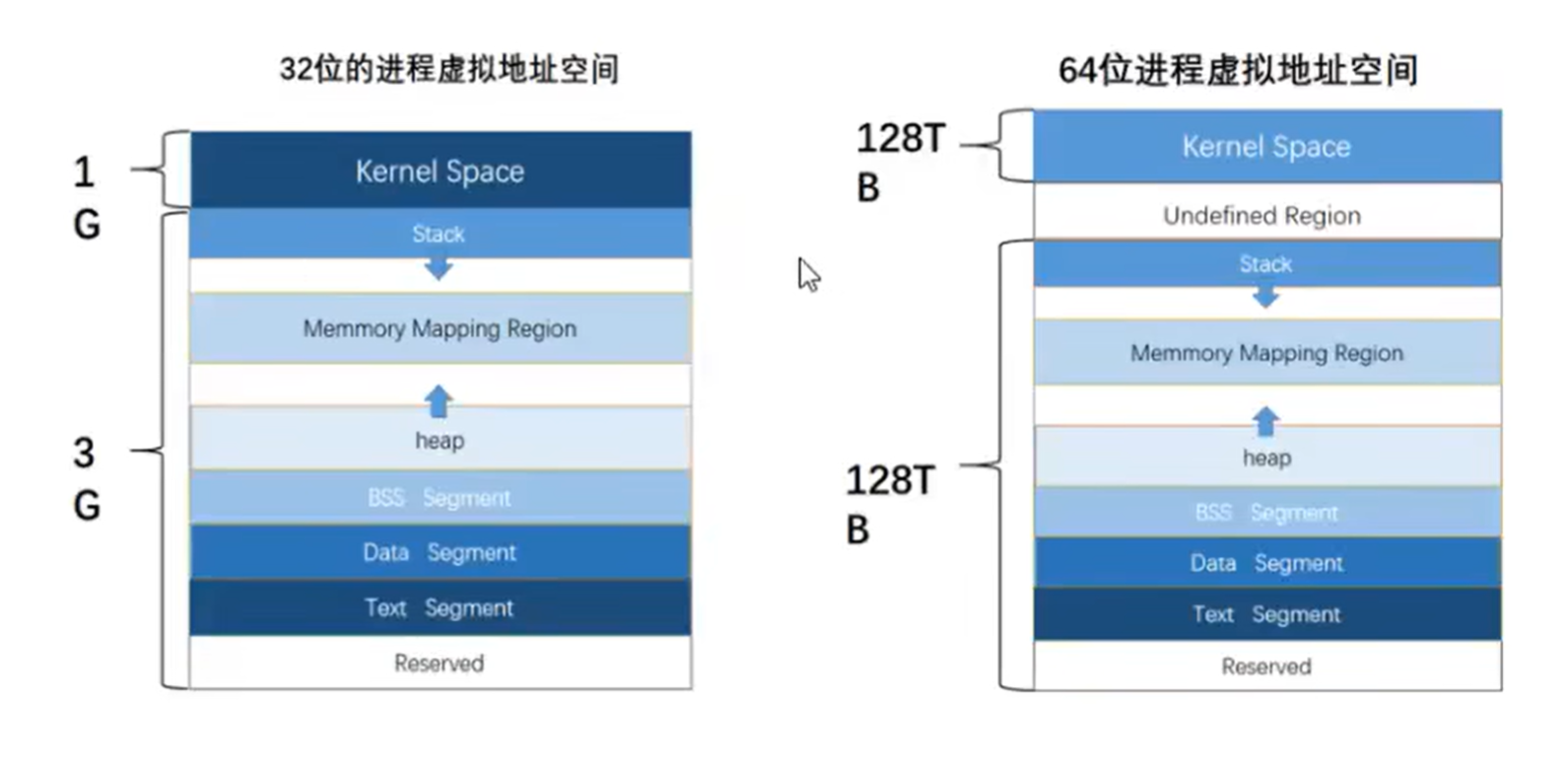
虚拟内存
实模式(可以直接操作物理地址)–>保护模式(用户只能访问虚拟地址,间接地访问物理地址)
graph LR
A["用户"]
B["OS"]
C["物理内存"]
A--系统调用-->B-->C
物理内存虚拟内存分配:
graph TD
A["操作系统内核空间(共享)"]
B["进程1"]
C["进程n(独立)"]
A-->B & ... & C
虚拟内存mmap段中动态链接库仅在物理内存中装载一份。
虚拟内存地址以字节编码,常以hex表示。
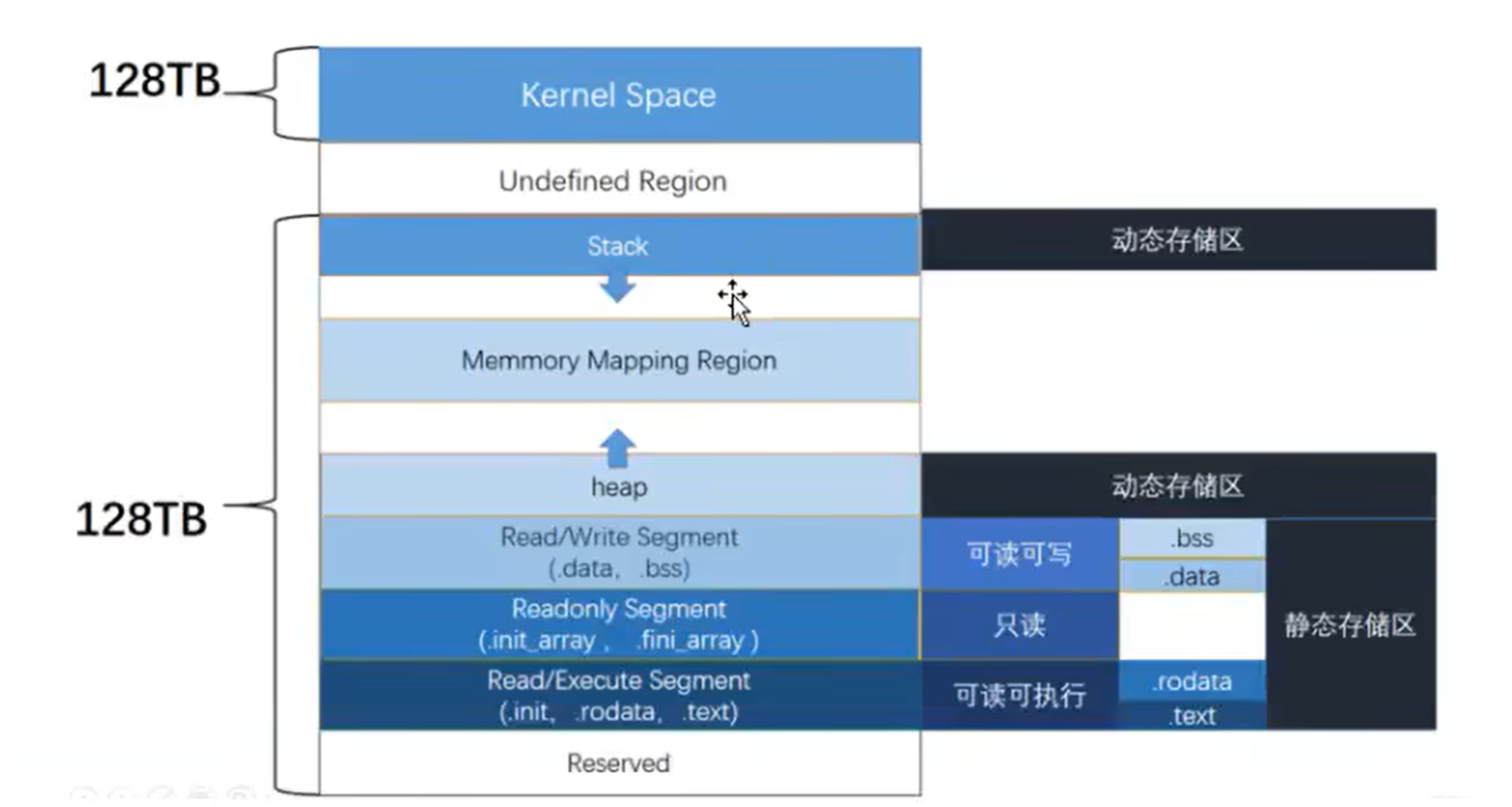
段(segment)与节(section)
段视图用于进程的内存区域的 rwx权限划分
节视图用于ELF文件编译链接时与在磁盘上存储时的文件结构的组织。
代码段(Text Seg)包含代码和只读数据:
- ==.text节==
- .rodata节
- .hash节
- …
- ==.plt节(解析动态库)==
- .rel.got节
数据段(Data segment)包含可读可写数据:
.data节
.got节
==.got.plt节(保存动态链接函数地址)==
==.bss节(不在磁盘占用空间,仅在内存占用,如未初始化的全局变量)==
…
程序数据在内存中的组织方式简例
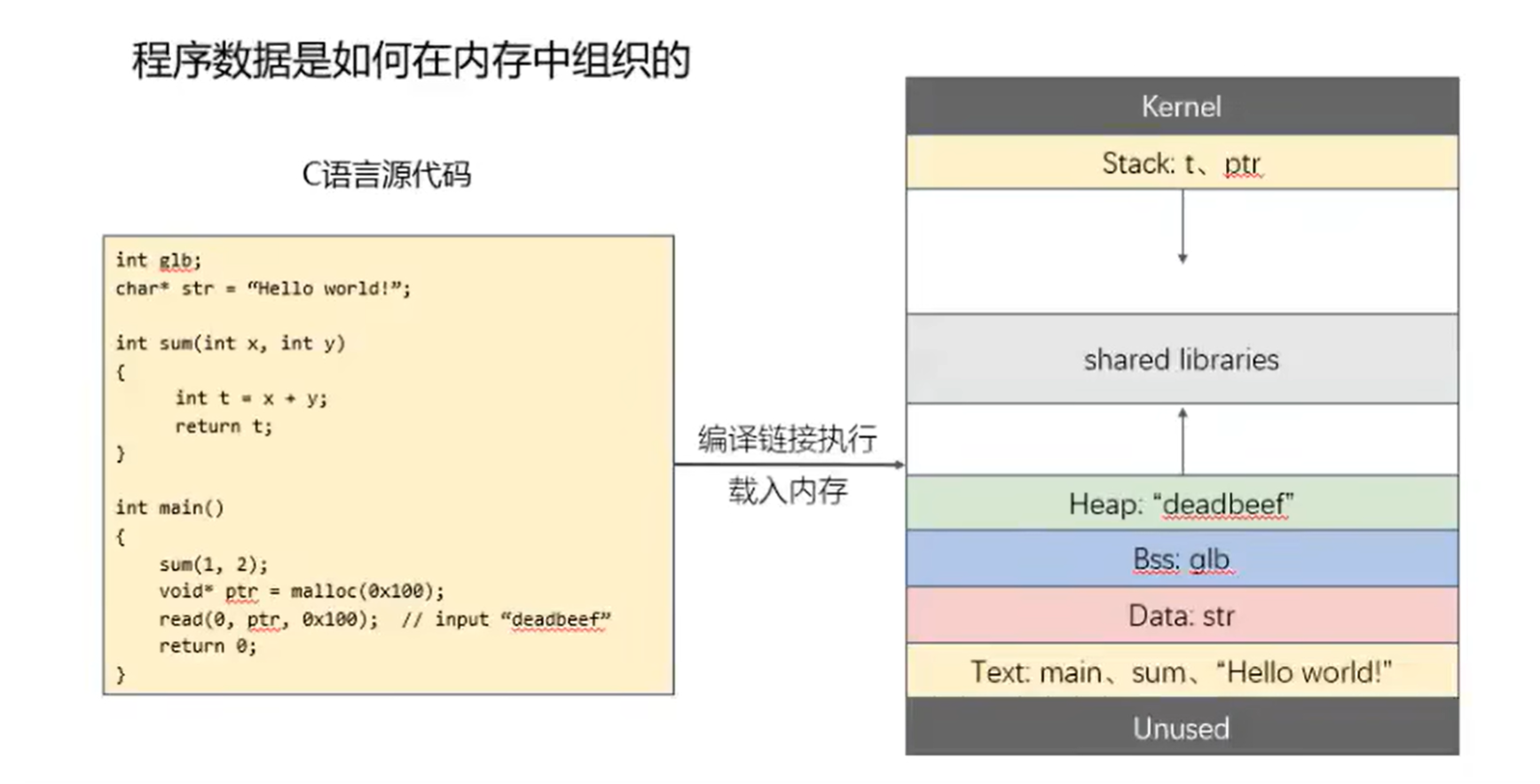
函数内局部变量存放在栈,形参不映射,32位形参压栈,64位用寄存器”rsi,rbi…”存。
大小端序
低位放低地址,高位放高地址。
程序的装载与进程的执行
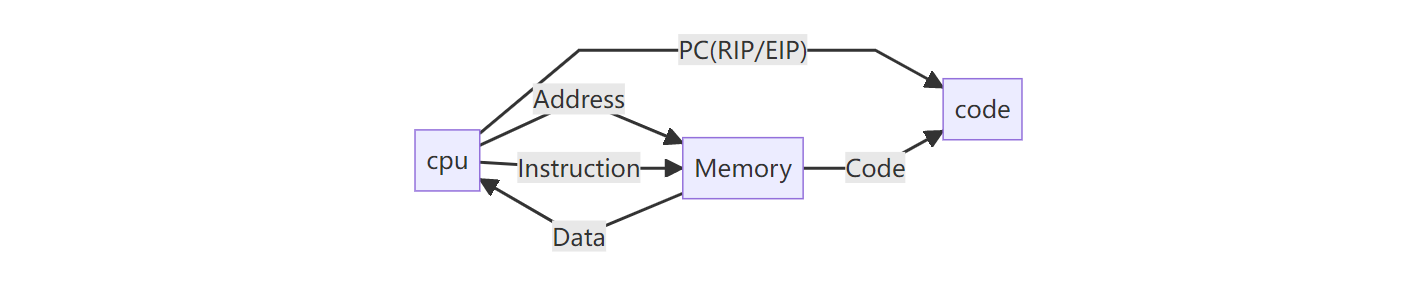
部分寄存器功能
- RIP(存放下一条执行指令的地址)
- RSP(存放当前栈帧的栈顶地址)
- RBP(存放当前栈帧的栈底地址)
- RAX(通用寄存器存放函数返回值)
静态链接的程序的执行过程
graph LR
A["$./binary"]
B["fork()"]
C["execve"]
D["kernel"]
E["_start"]
F["main()"]
A-->B-->C--user to kernel-->D--kernel to user-->E-->F
fork():复制自身内存创建新进程
_start:准备执行环境
动态链接
graph LR
A["kernel"]
B["ld.so"]
C["_start"]
D["__libc_start_main()"]
E["Init()"]
A-->B-->C-->D-->E-->...
asm
中括号[]:取括号内地址处的值
lea:取地址发送给指定寄存器
push:目标值压栈,SP-1
pop:将栈顶值弹出值指定位置,SP+1
leave:回复父栈帧,相当于mov esp,ebp pop ebp,进行栈顶和栈底指针的迁移,从而完成整个栈帧的复原。
ret:相当于pop rip,指令执行指针返回到父函数的下一条指令处。
xor eax,eax:清空eax
intel AT&T
区别不大,intel 被操作数在前,AT&T操作数在前
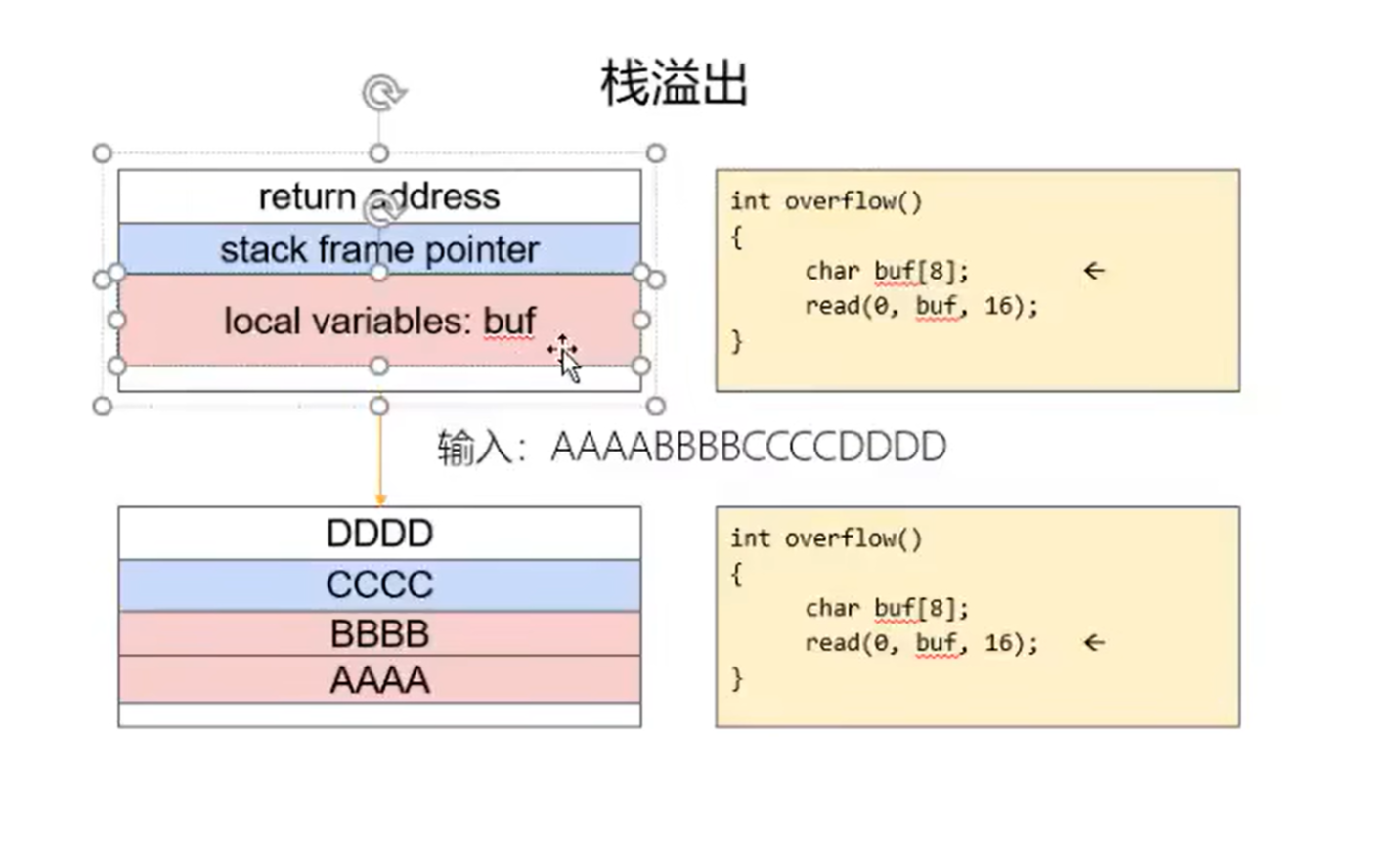
stack overflow
函数调用栈是一段连续的区域(高地址向低地址增长),用来保存函数运行时的状态信息,包括函数参数与局部变量等。
调用者caller的状态被保存在栈顶,被调用者callee的状态被保存在栈底。
函数调用栈的工作原理(x86)
call xxx不仅是jmp至目标函数,还将下一条指令的地址自动压入栈。
例如下面简单caller与callee的执行步骤:
1 | |
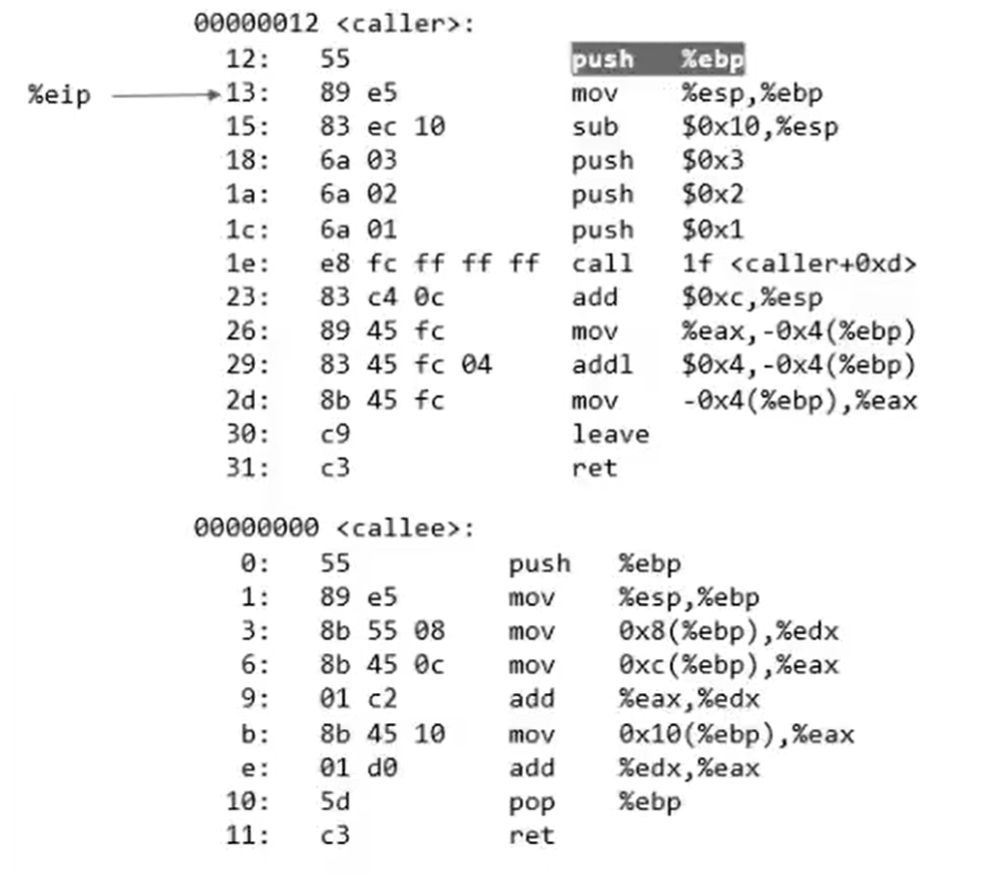
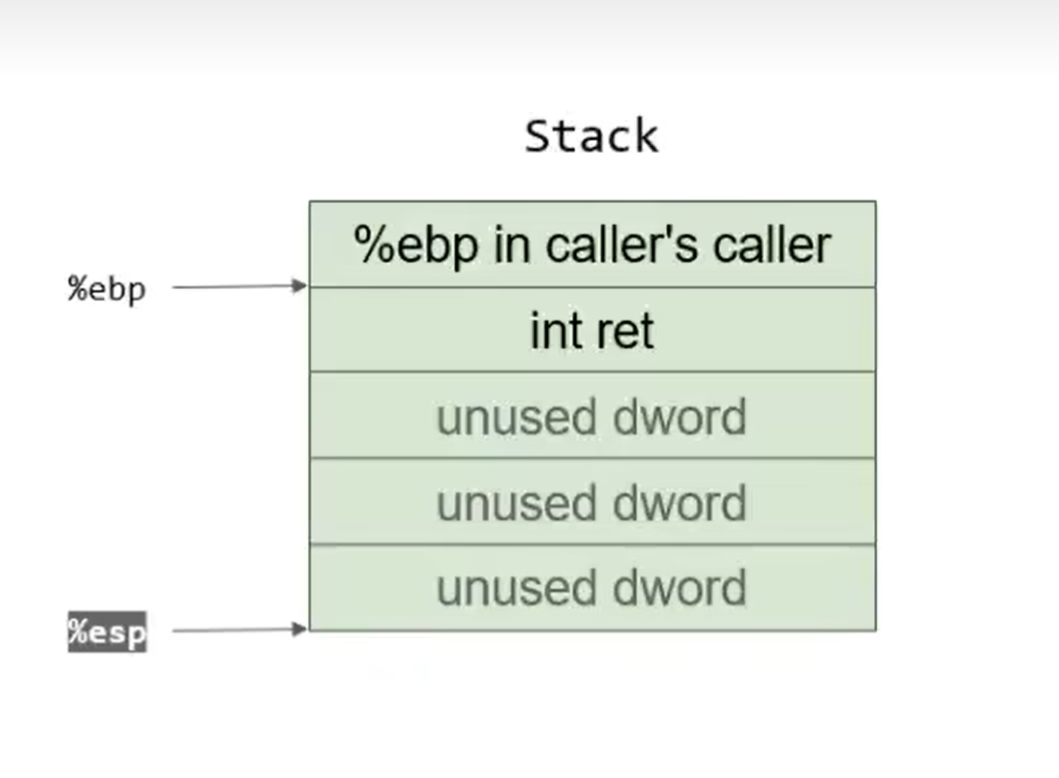
首先,caller中push %ebp; mov %esp,%ebp使得栈底存储caller的caller的栈底地址,之后让esp与ebp对齐。sub %0x10,%esp将esp向低地址偏移16,为后续变量留出空间:
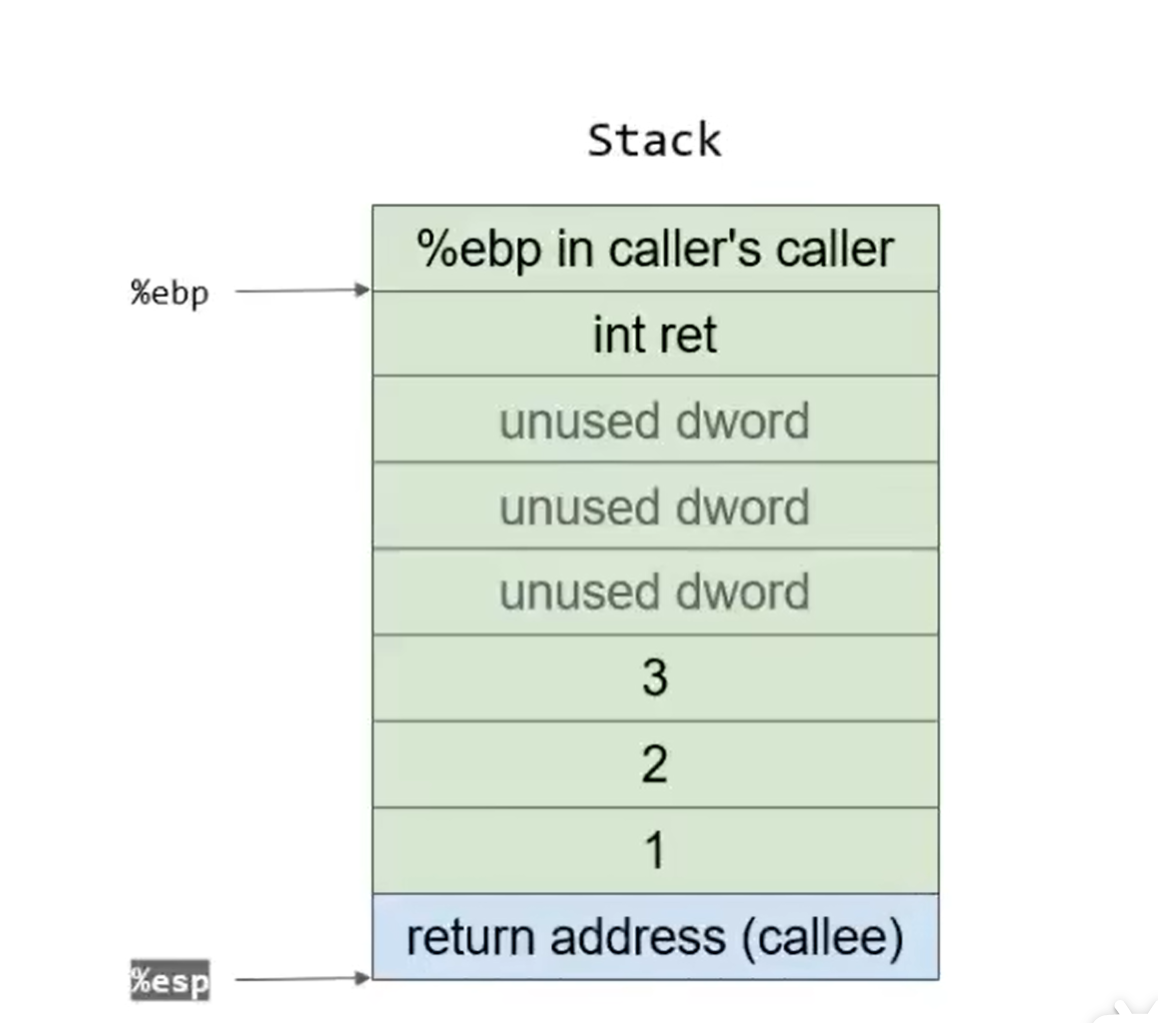
随后,把需要操作的三个数3,2,1逆序地压入栈中,开始callcallee,eip转向callee的0地址,同时将下一条指令也就是23处的地址压入栈中:
进入callee后,用与caller相同的方法在栈中保存caller的基地址,同时将ebp与esp对齐,完成栈迁移。同时由于callee没有再用到局部变量,所以直接使用寄存器,对原栈中的数据进行求和操作并存储在eax存储器:
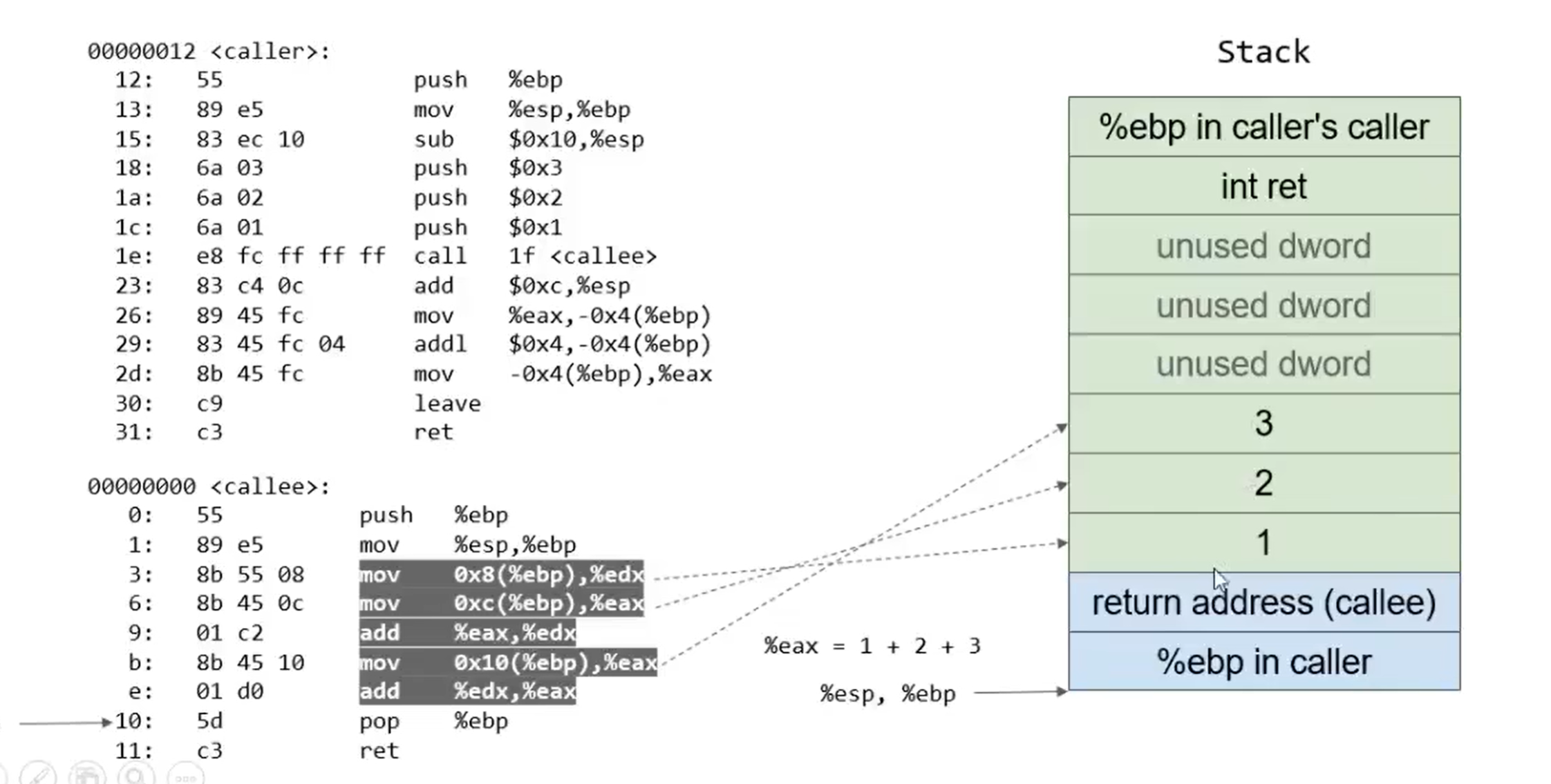
callee操作完成后,将栈顶的%ebp in caller弹出赋给ebp,将ebp还原到caller栈底,随后ret,进入caller的下一条指令:
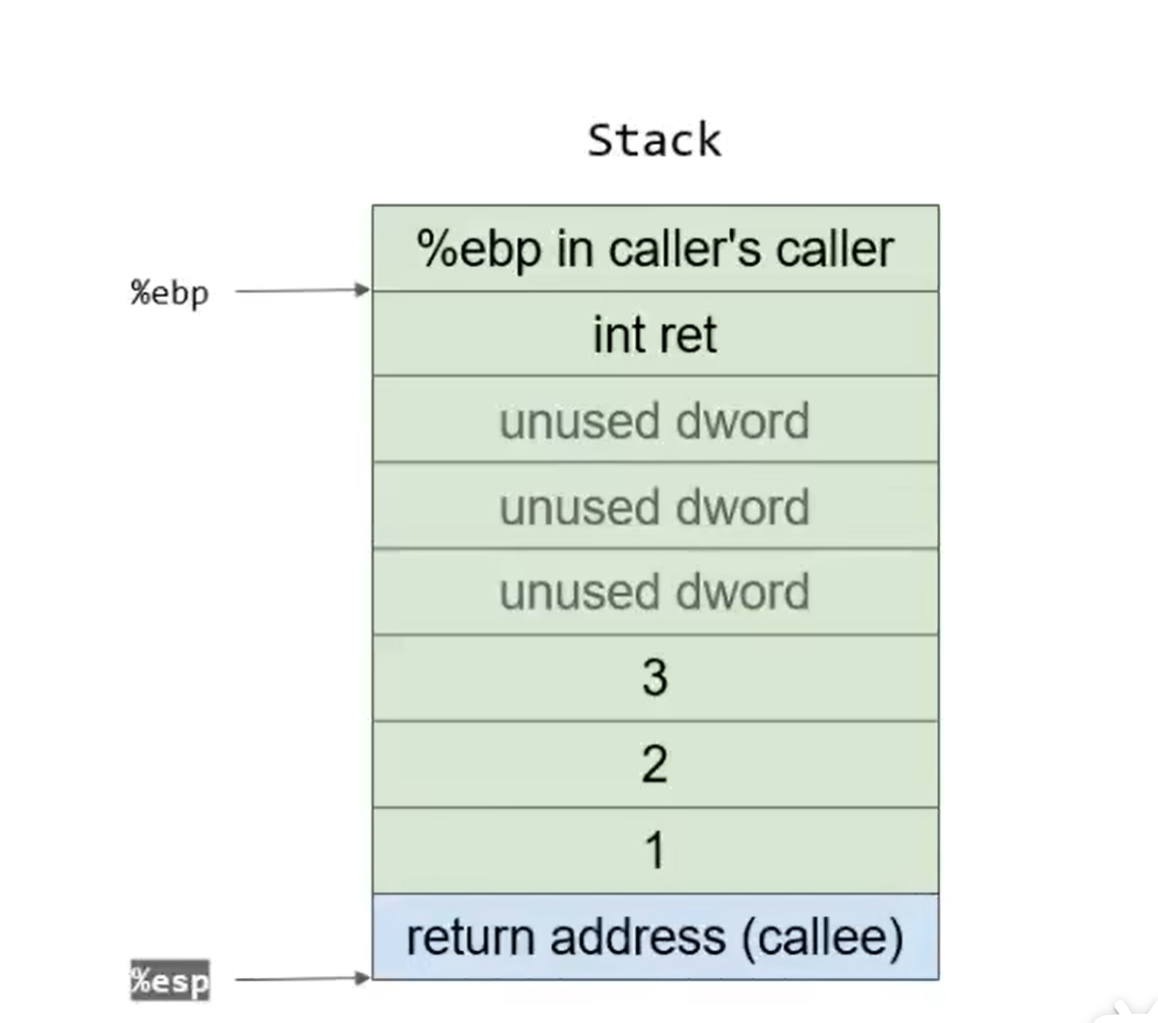
随后add $0xc,%esp将原来的三个数据”销毁”,栈顶指针指向3个值以前,随后mov %eax,-0x4(%ebp)将callee计算的结果存在int ret处,再进行ret+=4的计算,存储到eax中。
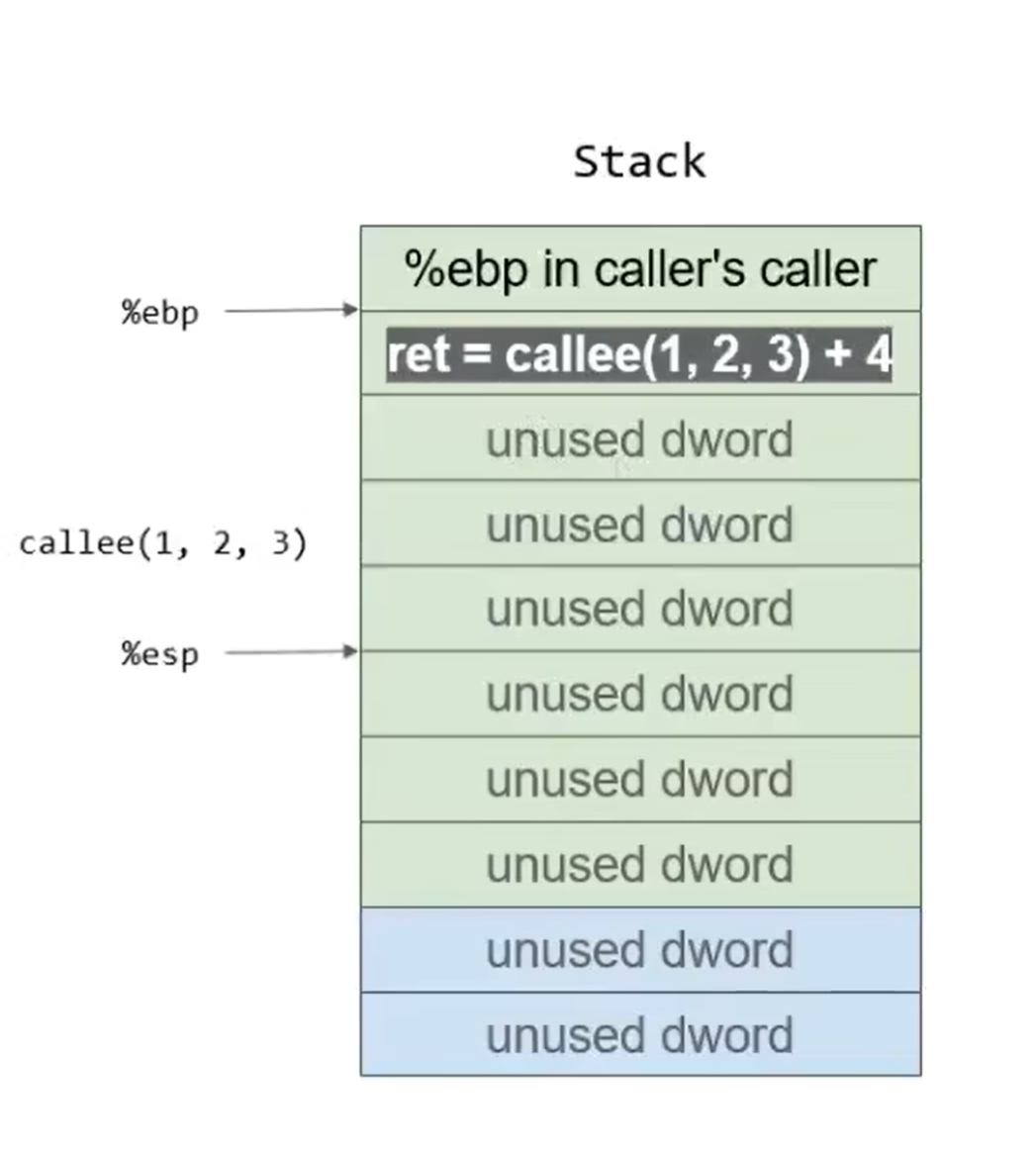
随后leave+ret再次完成栈迁移并回到caller的caller(祖父)处,完成调用:
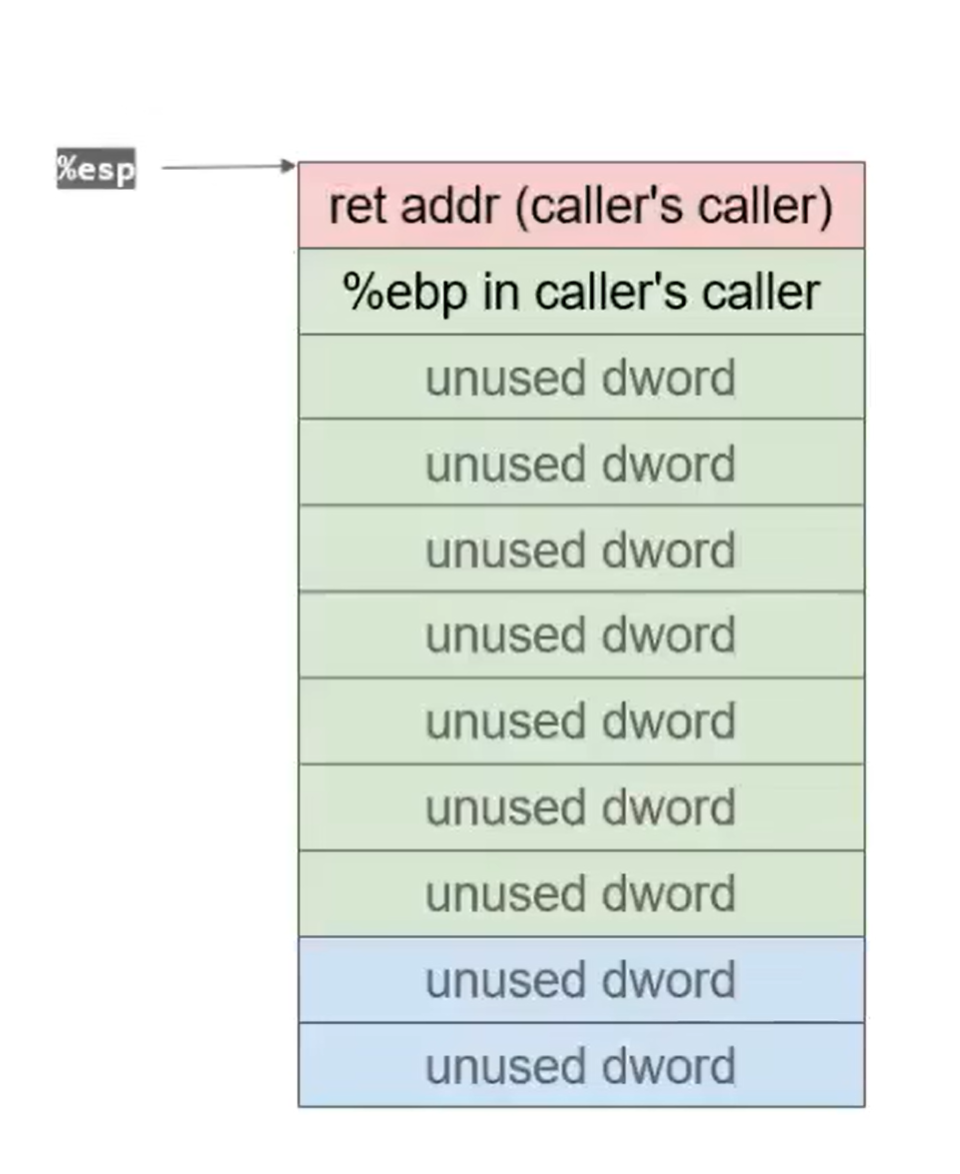
栈溢出攻击
攻击程序的目的:拿到shell控制服务器。当函数执行内部指令时无法获得程序控制权,只有当发生函数调用或结束函数调用时,程序控制权会在函数状态之间跳转,此时才可能修改函数状态。而控制程序最关键的部分在于eip/rip寄存器,因此我们的目的就是让eip/rip载入攻击函数的地址。
当函数结束调用执行ret时,caller的返回地址会被传给eip,因此我们可以写入溢出数据使得攻击指令的地址覆盖原来的返回地址,就可以让我们想要的地址载入eip。
我们可以在溢出数据中包含攻击指令,也可以在内存其他位置寻找可用的攻击指令,然后将返回地址覆盖为后门函数。
buffer overflow
缓冲区写入超长数据造成溢出。
Tools
IDA Pro:静态分析
pwntools:python辅助攻击模块
pwndbg:动态调试
checksec:检查保护
ROPgadget:寻找获取ROP
one_gadget:寻找获取shell
IDA Pro
Tips:
function window中,写死的函数用白色标识,动态链接的表项用粉色表示。
显示机器码:Option–>Number of opcode bytes(non-graph)设定长度。
C与Asm对照:Ctrl+A全选–>Copy to assembly
pwntools
调用库:
from pwn import *设置io变量:本地:
io=process("./test");远程:io=remote("localhost",port)接受字符串:接收一行:
io.recvline();接收所有:io.recv()发送数据:
io.send(xxx),括号中必须是字节流,若是整数用p32()/p64()转化,字节串b’ ‘包裹,用“+”连接。不可见字节可用”\x”发送;io.sendline(xxx),在末尾加\n。进入交互:
io.interactive()
linux自带base64编码:
1 | |
pwndbg
基本命令:
进入调试:
gdb 程序名下断点:
b *地址(0x形式)b 函数名取消断点:d 断点序号运行:
r步进:s步过:n栈视图:
stack x显示栈的x项
窗口:虚拟内存分布窗口:
vmmapRegister寄存器
Disasm反汇编窗口
Stack栈窗口,显示esp和ebp,低地址在上,数据从上向下写
若一段数据(如栈中)存放了指针,则会显示指针指向的内容
程序在gdb中显示的地址与真实地址可能不符,但偏移一定是正确的。
ret2text
利用程序本身的后门函数。
buuctf rip
payload:
1 | |
其中0x401186为系统调用shell后门函数的位置。
需要+1的原因或执行ret的原因:ubuntu18以上的64位程序,system需要进行栈对齐,所以应跳过一项栈指令,这样才能使得栈对齐。
详细:关于ubuntu18版本以上调用64位程序中的system函数的栈对齐问题 - ZikH26 - 博客园
ret2shellcode
由于程序不太可能真的给出后门函数,所以需要自己构造shellcode。
初期将shellcode直接写入栈缓冲区,开启NX保护后栈缓冲区不可执行,故改为将shellcode向bss中写入或者向堆中写入,并用mprotect赋予其可执行权限。
如何获得shellcode?使用pwntools的shellcraft和asm模块。
1 | |
可以获得调用shell的shellcode硬编码。如果是64位下:
1 | |
w权限和x权限理应不能同时出现。
由于ASLR的存在,所以即使栈段可执行,我们也不知道栈的真实位置,所以我们并不知道我们写入数据的真实位置。但是Text/Data/Bss都可以找到,因为他们是ELF的固定内容,若PIE未开启,我们就可以定位到Bss的位置。因此我们可以将ret的位置覆盖为Bss的位置,并在Bss中写入shellcode,这样就可以使得函数ret到shellcode,劫持服务器。
某个ret2shellcode 32位题目的payload,输入会被拷贝到全局变量buf中:
1 | |
protect
NX
栈不可执行。
canary
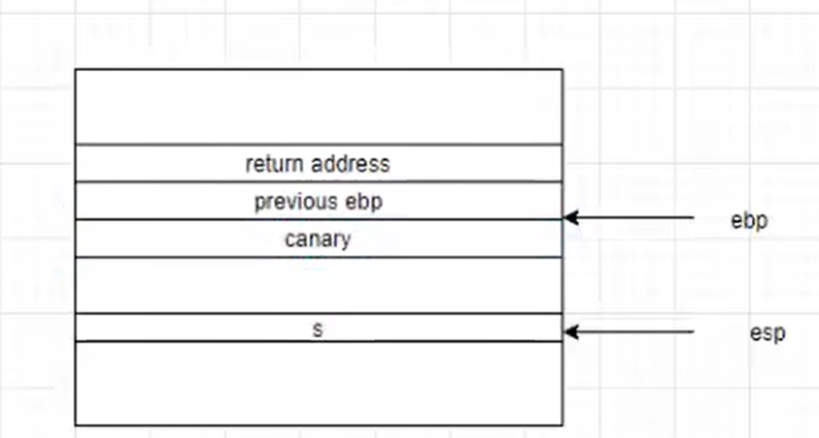
如图,打开canary保护的程序创建栈帧时,会在ebp的低地址的位置放置一段canary随机值,销毁栈帧时会首先检查canary是否被更改,如果更改那么程序直接崩溃退出。
ASLR
随机化栈,共享库,堆。
PIE
随机化ELF文件本体。
ROP返回导向编程
系统调用
系统调用:OS给User的编程接口,是提供访问操作系统所管理的底层硬件的接口。本质上是一些内核函数代码,以规范的方式驱动硬件。x86通过int 0x80指令进行系统调用,amd64通过syscall进行系统调用。
例如x86中:
1 | |
以上调用可以执行execve("bin/sh",NULL,NULL)
动态链接库
ldd查看可执行程序所用到的动态链接库。
调用库函数如printf时,实际的函数实现在libc文件中,编译时将其载入shared library,程序调用时指向这个函数。
Ret2syscall-ROP
例如我们想执行execve("bin/sh",NULL,NULL)这段指令以拿到shell,可程序中并没有现成的连续指令。但我们可以用组成该段程序的代码片段来组成我们想要的指令。
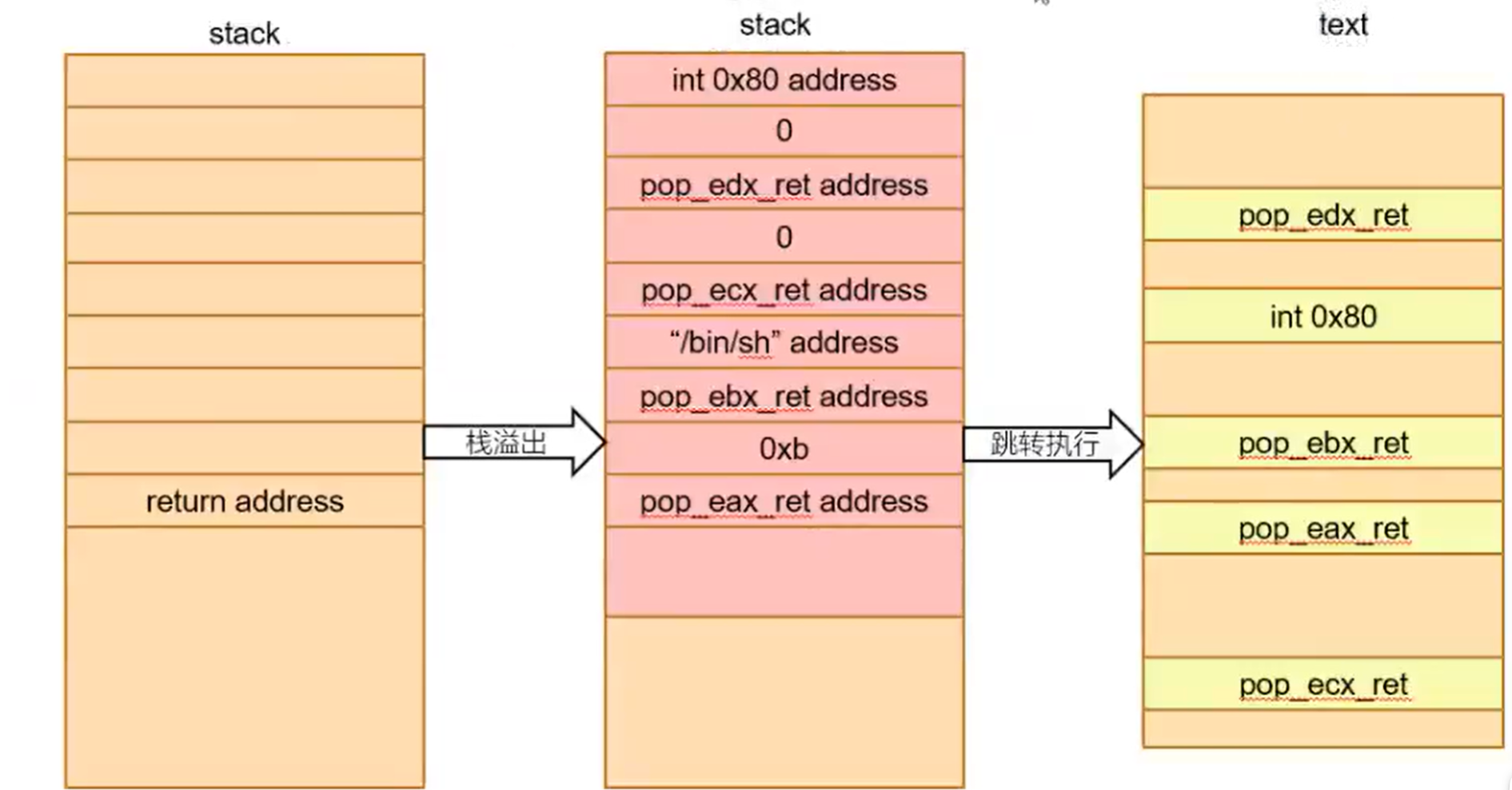
栈溢出后,溢出数据形成了ret-call-ret…链,从而形成了整个指令。
寻找这样的组件(gadget)需要ROPgadget工具,用例:
1 | |
该命令可以找到二进制程序中的pop eax ;retgadget。
ret2syscall
确认没有后门函数后,准备打rop链。
首先用ROPgadget工具寻找pop retgedget,组合gedget,先填垃圾数据到覆盖esp/rsp,然后将构造好的gedget和数据依次写入payload,使用pwntools的flat函数可以将列表中的每一项转化为字节型,不足1字长的会补全。例如:
1 | |
pwntools创建elf文件对象以及相关方法:
1 | |
动态链接过程
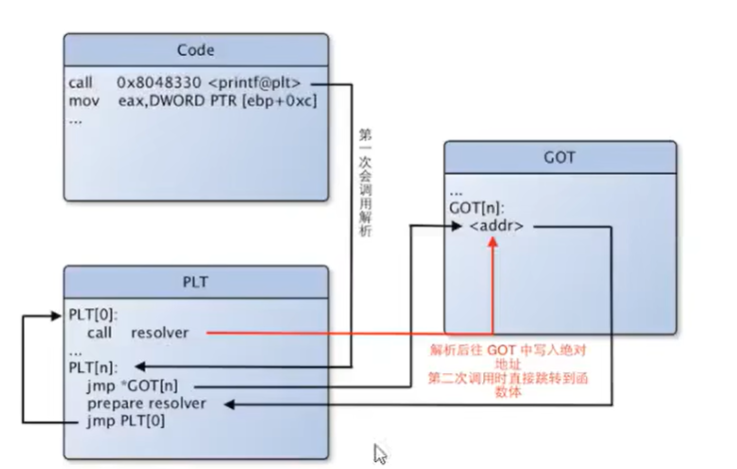
静态链接和动态链接区别:静态链接编译时会将库函数全部写入文件,而动态链接只是做标识,表示将要用到某个库,因此静态链接文件要比动态链接文件大很多。
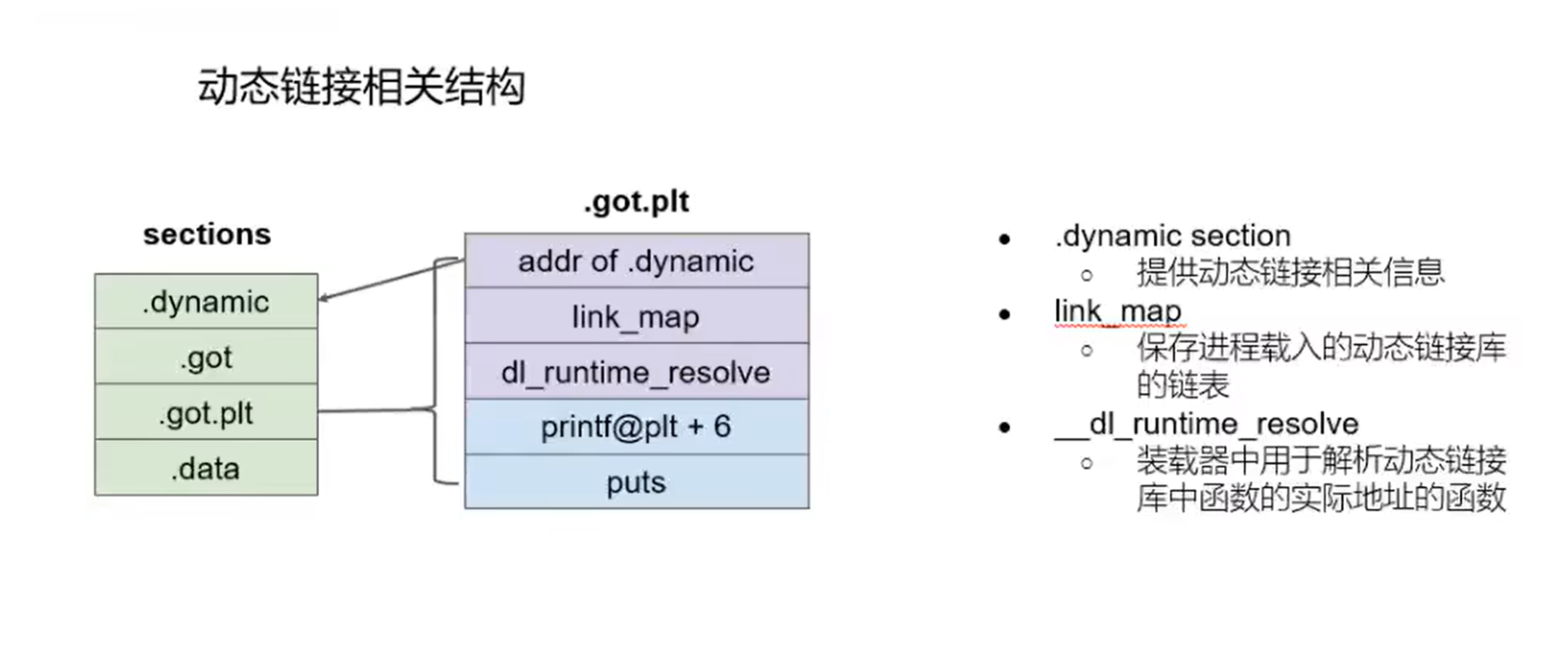
调用库函数foo的过程:
进程首次调用foo时,跳转到.plt中的foo表项
.plt的foo表项立即跳转至.got.plt的foo表项,由于此时got表中目前没有foo的真实位置,因此跳回.plt
向栈中压入相关参数,为后续解析函数做好准备,随后
jmp到got对应位置进行解析。__dl_runtime_resolve函数解析foo的真实地址,填入.got.plt。
第二次及后续调用foo时,到plt->got后,由于第一次调用时已经填入了foo的真正地址,所以能够直接到达foo的真实地址。
pwndbg
x/nx 地址 显示地址的内容,n填要看的长度。
start进入main函数第一行或进入程序入口。
backtrace显示函数调用栈,呈现函数调用的父子关系。
return退出当前函数
ret2libc
动态链接的文件往往不能找到足够的gadget,因此我们的思路改为将rop链导向libc。
例如,程序中没有直接system(“/bin/sh”),但是出现了system函数,这就会在程序plt表项中添加属于system()库函数的一项。因此只要我们将程序流劫持到system()plt表项处,就可以调用该函数。再传入参数”/bin/sh”即可。

got表项与实际函数的关系:
graph LR
A["system@got"]
B["&system"]
C["code of system in libc"]
A-->B-->C
因此我们要跳转到的是&system而不是system@got
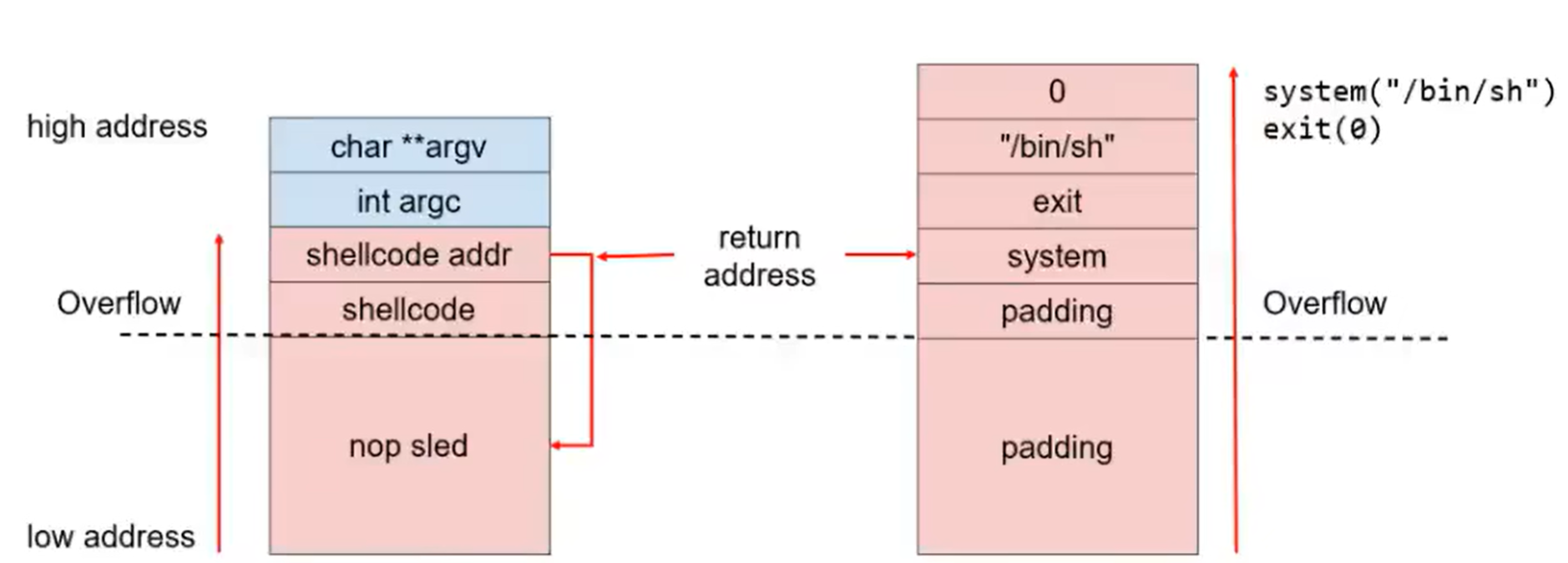
ret2shellcode,shellcode写入栈,nop滑梯应对ASLR:在shellcode下方填入足够长的nop链,指针指向确定的位置,这样大概率可以指向nop链的中间某个位置,这样程序就会一路执行nop到shellcode。
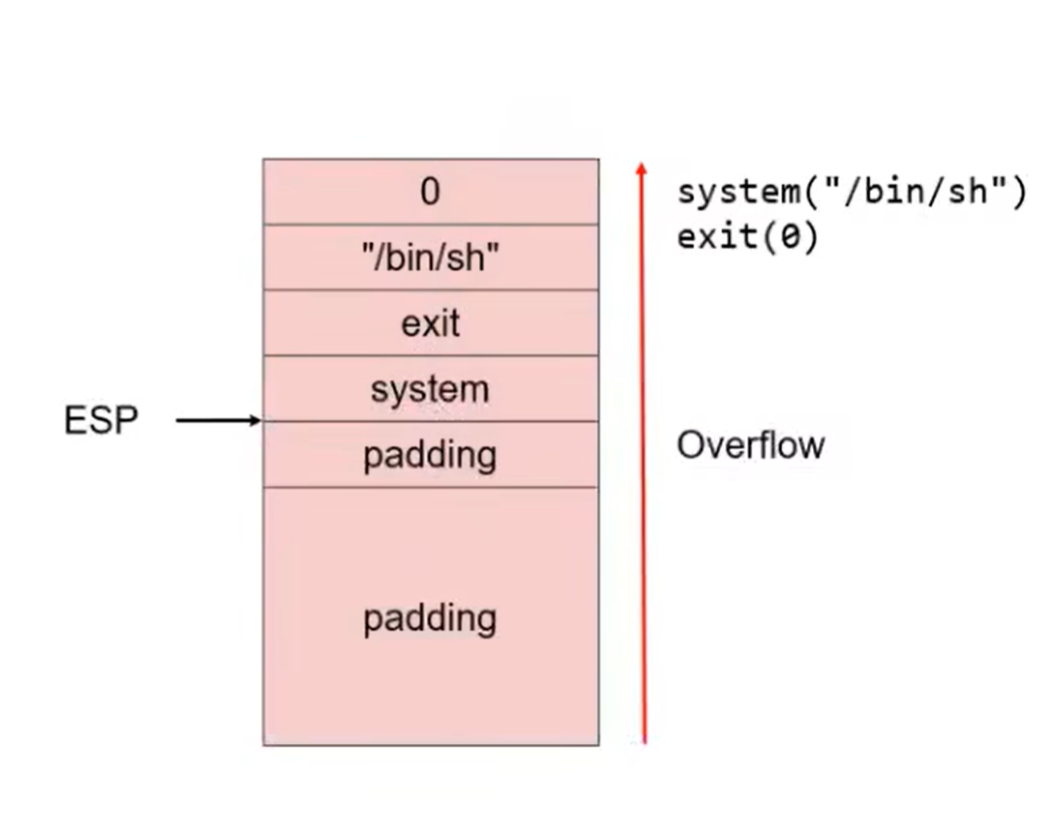
为什么参数要填到上面两个字长的位置?因为system,exit的第一条指令总是push ebp,此时ebp会占一个字长,那么函数想要调用传入的参数,就要向上数两个字长跳过caller’s ebp和retaddress才能找到参数。有时调用更多函数(3个及以上)的时候需要使用pop_retgadget来构造。题目中没有给”/bin/sh”时,还需要调用read将其读入内存。
如何找到库函数的地址?回顾动态链接首次调用system的过程:
graph TD
A["call system"]
B["system@plt"]
C["Resolver"]
D["system@got"]
E["system@glibc"]
A-->B--1-->D--2-->B--3-->C--4-->D-->E